
布隆过滤器
1、布隆过滤器原理
1.1 什么是布隆过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
主要用于判断一个元素是否在一个集合中,0代表不存在某个数据,1代表存在某个数据。
总结: 一个元素一定不存在 或者 可能存在! 存在一定的误判率{通过代码调节}
1.2 使用场景
大数据量的时候, 判断一个元素是否在一个集合中。解决缓存穿透问题
1.3 原理
*存入过程*
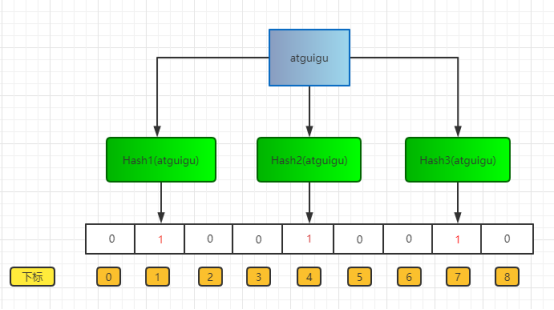
布隆过滤器上面说了,就是一个二进制数据的集合。当一个数据加入这个集合时,经历如下:
-
通过K个哈希函数计算该数据,返回K个计算出的hash值
-
这些K个hash值映射到对应的K个二进制的数组下标
-
将K个下标对应的二进制数据改成1。
例如,第一个哈希函数返回x,第二个第三个哈希函数返回y与z,那么: X、Y、Z对应的二进制改成1。
如图所示:
查询过程
布隆过滤器主要作用就是查询一个数据,在不在这个二进制的集合中,查询过程如下:
1、通过K个哈希函数计算该数据,对应计算出的K个hash值
2、通过hash值找到对应的二进制的数组下标
3、判断:如果存在一处位置的二进制数据是0,那么该数据不存在。如果都是1,该数据存在集合中。
1.4 布隆过滤器的优缺点
- 优点
-
由于存储的是二进制数据,所以占用的空间很小
-
它的插入和查询速度是非常快的,时间复杂度是O(K),空间复杂度:O (M)。
K: 是哈希函数的个数
M: 是二进制位的个数
- 保密性很好,因为本身不存储任何原始数据,只有二进制数据
- 缺点:
添加数据是通过计算数据的hash值,那么很有可能存在这种情况:两个不同的数据计算得到相同的hash值。

例如图中的“张三”和“张三丰”,假如最终算出hash值相同,那么他们会将同一个下标的二进制数据改为1。
这个时候,你就不知道下标为1的二进制,到底是代表“张三”还是“张三丰”。
由此得出以下缺点:
1、存在误判
假如上面的图没有存 "张三",只存了 "张三丰",那么用"张三"来查询的时候,会判断"张三"存在集合中。
因为“张三”和“张三丰”的hash值是相同的,通过相同的hash值,找到的二进制数据也是一样的,都是1。
误判率:
受三个因素影响: 二进制位的个数m, 哈希函数的个数k, 数据规模n (添加到布隆过滤器中的数据)

已知误判率p, 数据规模n, 求二进制的个数m,哈希函数的个数k {m,k 程序会自动计算 ,你只需要告诉我数据规模,误判率就可以了}

ln: 自然对数是以常数e为底数的对数,记作lnN(N>0)。在物理学,生物学等自然科学中有重要的意义,一般表示方法为lnx。数学中也常见以logx表示自然对数。
2、删除困难
还是用上面的举例,因为“张三”和“张三丰”的hash值相同,对应的数组下标也是一样的。
如果你想去删除“张三”,将下标为1里的二进制数据,由1改成了0。
那么你是不是连“张三丰”都一起删了。
2、实现方式
2.1 初始化skuId的布隆过滤器
我在service-product模块中操作
2.1.1 RedisConst常量类
public class RedisConst {
public static final String SKUKEY_PREFIX = "sku:";
public static final String SKUKEY_SUFFIX = ":info";
//单位:秒
public static final long SKUKEY_TIMEOUT = 24 * 60 * 60;
// 定义变量,记录空对象的缓存过期时间
public static final long SKUKEY_TEMPORARY_TIMEOUT = 10 * 60;
//单位:秒 尝试获取锁的最大等待时间
public static final long SKULOCK_EXPIRE_PX1 = 100;
//单位:秒 锁的持有时间
public static final long SKULOCK_EXPIRE_PX2 = 10;
public static final String SKULOCK_SUFFIX = ":lock";
public static final String USER_KEY_PREFIX = "user:";
public static final String USER_CART_KEY_SUFFIX = ":cart";
public static final long USER_CART_EXPIRE = 60 * 60 * 24 * 30;
//用户登录
public static final String USER_LOGIN_KEY_PREFIX = "user:login:";
// public static final String userinfoKey_suffix = ":info";
public static final int USERKEY_TIMEOUT = 60 * 60 * 24 * 7;
//秒杀商品前缀
public static final String SECKILL_GOODS = "seckill:goods";
public static final String SECKILL_ORDERS = "seckill:orders";
public static final String SECKILL_ORDERS_USERS = "seckill:orders:users";
public static final String SECKILL_STOCK_PREFIX = "seckill:stock:";
public static final String SECKILL_USER = "seckill:user:";
//用户锁定时间 单位:秒
public static final int SECKILL__TIMEOUT = 60 * 60 * 1;
// 布隆过滤器使用!
public static final String SKU_BLOOM_FILTER="sku:bloom:filter";
}
2.1.2 修改启动类
@SpringBootApplication
@ComponentScan({"com.atguigu.gmall"})
@EnableDiscoveryClient
public class ServiceProductApplication implements CommandLineRunner {
@Autowired
private RedissonClient redissonClient;
public static void main(String[] args) {
SpringApplication.run(ServiceProductApplication.class,args);
}
//初始化布隆过滤器
@Override
public void run(String... args) throws Exception {
//获取布隆过滤器
RBloomFilter<Object> bloomFilter = redissonClient.getBloomFilter(RedisConst.SKU_BLOOM_FILTER);
//初始化布隆过滤器:计算元素的数量 比如预计有多少个sku
bloomFilter.tryInit(10001,0.001);
}
}
2.2 给商品详情页添加布隆过滤器
1、查看商品详情页添加布隆过滤器
操作模块:service-item
更改ItemserviceImpl.item方法

2、添加商品sku加入布隆过滤器数据
操作模块:service-product
更改ManageServiceImpl.saveSkuInfo方法

这样就避免了别人用一个不存在的key去疯狂攻击我们的缓存数据库。
我们在分布式锁中将查询结果是null的也进行缓存,但是如果有人用随机数去疯狂请求我们的接口,那我们的Redis可能会扛不住,所以在这里用布隆过滤器,只需要在初始化的时候,指定我们存储数据的数据量和可以承受的误判率即可。
布隆过滤器指导有哪些数据,这样别人使用随机数攻击的时候直接就给他返回,不用再去查Redis了。
- 0
- 0
-
分享